
Situational Awareness - Chapter 1 (Tech-Challenged Version)

*100% Organic Human Writing by a Tech Impostor.
Look. The models, they just want to learn. You have to understand this. The models, they just want to learn.
Ilya Sutskever (circa 2015, via Dario Amodei) – Amodei is the guy (CEO) from Anthropics.
That's how the former Superalignment team at OpenAI, Leopold Aschenbrenner started his paper, Situational Awareness, back in June 2024. He was fired from OpenAI after writing a memo to the board, raising concerns about a "major security incident." :)
Yes, I know - it's been a while, ages ago! But trust me, it's still fresh information, also took me ages to read, understand, and actually learn something from it. I’m not one of those "real tech people," just more of an aficionado, curious observer, intruder, impostor than a 'tech insider' - so trying to understand this stuff, feels like learning German.
But you know what? That's exactly why I'm writing this. I have a blog, I have thoughts, and sometimes the best way to make sense of complex ideas is to write about them.
In this paper, he dives into how we should start thinking about the crazy-fast changes ahead. In his view, 2027 is when AGI will show up - and ASI might not be far behind, maybe even by 2028–2030.
This is a long one, but I’m not adding a TL;DR - every bit of it is worth your time. Leopold dedicated Situational Awareness to Ilya Sutskever, and honestly, so will I.
Counting OOMs
We will talk about “Counting OOMs” - which means what exactly, Viktoria? Well, real techies know the meaning, but the rest of the earthling don't.
OOM refers to Order Of Magnitude.
10x = 1 order of magnitude. 1 → 10 → 100 → 1,000.
Each jump is called “one order of magnitude.” So, from 1 to 1,000, it’s three steps, or it has gone up three orders of magnitude.
Why should we care? Because it’s how we measure progress and guess what might happen next.
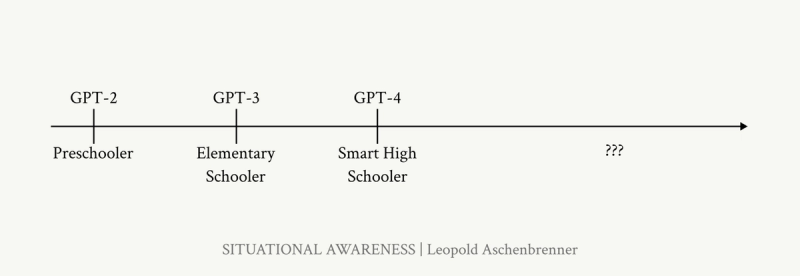
In the past four years, the progress was (if we scale GPT):
- GPT2 – preschooler (2019)
- GPT3 – elementary schooler (2020)
- GPT4 – smart high schooler (2023). Let’s be honest here, I never had a classmate in high school who could be as smart as GPT4 and as fast. I’m talking about an end-user view, not official benchmarks.
GPT-4 took about 4 OOMs to grow from GPT-2 - preschool to high school in four years. Now we’re hearing AGI predictions for 2027, which might need another 4 to 5 OOMs.

Anyway - while updating this, OpenAI casually dropped o3 and o3-mini with wild benchmarks. Of course, AGI is already being mentioned on X.
Results of o3 in ARC-AGI - apparently a quite hard benchmark, designed to compare artificial intelligence with human intelligence.
- GPT-3? 0% in 2020.
- GPT-4o? 5% by 2024.
- o1? 32%.
- And now o3-high? 87.5%.
That’s like skipping 11 years of progress overnight.
I’m not convinced yet. OpenAI’s been loud before, and most models still struggle to outperform Sonnet 3.5 when it matters. Maybe they actually improved the algorithms, or maybe AGI slipped out the backdoor when Sam got fired.
Let’s wait and see, I will be waiting for LeCun's feedback.
Skeptics Keep Losing Bets
Over and over again, year after year, skeptics have claimed “deep learning won’t be able to do X” and have been quickly proven wrong. If there’s one lesson we’ve learned from the past decade of AI, it’s that you should never bet against deep learning.
— Leopold Aschenbrenner
Leopold lists some notable examples:
- Yann LeCun (2022), of course the first one is LeCun. Not only he has issues with Elon Musk but seems with LLMs too. He predicted even GPT-5000 wouldn’t reason about physical interactions. GPT-4 did it a year later.
- Gary Marcus’s “walls” were repeatedly overcome by GPT-3 and GPT-4.
- Prof. Bryan Caplan bet no AI would score an A on his economics midterm by 2029. GPT-4 scored an A in 2023, two months after its release.

The lesson? Never bet against deep learning.
2027: The Omen of AGI

Counting the OOMs, in 2027 we may expect another jump, as from GPT-2 to GPT-4, but this time, toward AGI (if we count conspiracy theories).
But before we try to predict the future, we need to understand the past, even if this may sound like an episode from LOST.
Let’s decompose the progress we had until now, what really happened there?
Leopold identifies three key factors:
- Compute
- Algorithmic efficiencies
- Unhobbling

1. Compute
Now, much larger computers are used to train models. GPT-4’s training required 3,000x–10,000x more compute than GPT-2, but it cost the same as GPT-3.
2. Algorithmic Efficiencies
These act as compute multipliers and have been underrated.
Leopold introduces two types:
- Improving existing processes - getting the same results while using less compute.
- Unlocking entirely new capabilities, letting us achieve things that weren’t possible before.
The issue? It’s hard to measure these improvements since labs keep their internal data under wraps. (Still, EpochAI estimates a 4 OOMs gain in efficiency over the past eight years - a big deal.)
How do we know this?
Look at GPT-4 - it cost about the same to train as GPT-3, but the difference in what it could do was massive. So, where did the gains come from? Not more money, but better algorithms.
The Data Wall
Here’s a reminder (not my quote): “If something is free, you are the product.” Why?
Because we’re running out of internet data. Leopold wrote about this six months ago, and honestly, I think we’d already hit the wall. Out of the ~100T tokens of raw data on the internet, only about 30T are actually useful. And since Llama 3 was trained on over 15T tokens, we’ve kind of used up all the good stuff.
Even with compute the size of a country, without enough data or better algorithms, it’s all useless.
Researchers are testing a bunch of strategies to solve this problem - synthetic data, self-play (which isn’t a bad idea), and reinforcement learning (RL).
We’re running out - or maybe we’ve already run out - of useful data to train on. But even if there was more data, there’s still a bigger issue.

Modern large language models (LLMs) are like printers: they chew textbooks but don’t actually understand them.
It’s like when you’re "skimming "reading" an article while thinking over what you should have said in that argument last week. (No, this isn’t ChatGPT - this one’s all me. I’m just running low on creativity today.)
Anyway, back to the point: LLMs are trained by throwing massive amounts of data at them. But if these models are meant to mimic human intelligence, they need to learn how humans learn - and we don’t learn that way. Memorizing a textbook might get you good grades, but it won’t make you understand the material. Same with LLMs.
Humans learn by reading, debating, making mistakes, trying again, solving problems, and failing repeatedly until it clicks. LLMs? They’re stuck in the memorization phase. Understanding and memorizing it's not the same.
And since there’s a data shortage, better algorithms are the solution. They can help models learn more from less, making every bit of data count.
Most models are free, right? Which means people like me - and you - have contributed to training them without even realizing it. We’re the product.
But here’s the twist: older models, like AlphaGo, actually did learn more like humans.
- Step 1: AlphaGo started by imitating expert human Go games to build a solid foundation.
- Step 2: It then played millions of games against itself, refining its skills and discovering brilliant moves like “move 37” - something no human would’ve thought of. Watch the documentary, I highly recommend it.
Now imagine if LLMs could do more than just memorize. If they could actually work through problems, test ideas, and learn like humans, the potential would be massive.
But here’s the thing: right now, LLMs remind me of those privileged kids at fancy schools. They’ve got everything handed to them - fancy uniforms, expensive tutors - but if the education is not good, if quality learning is not priority, whey will be mediocre.
And that’s the problem. It doesn’t matter who’s ahead in AI today. Sooner or later, they’re all going to hit a wall unless they stop dumping data and focus on better algorithms. (I though Q-strawberry was that, just a better algorithm)
LET LLMs FREE, like Britney.
3. Unhobbling: Unlocking the Beast
So, we’ve talked about compute and algorithmic efficiencies. Now let’s move on to something that took me way longer to wrap my head around: unhobbling.
WTF is unhobbling? Oh, this could get so philosophical. My favorite part.
Unhobbling is about taking off the artificial constraints that keep an LLM from reaching its full potential.
As Matt Busche (researcher) puts it, "It’s like forcing a talented artist to use crayons instead of proper tools. The reasons for the hobbling are well-intentioned - it’s kind of like keeping a powerful dog on a leash to keep things safe and under control."

To unlock their true capabilities, LLMs need:
- Reinforcement Learning from Human Feedback (RLHF)
- Chain-of-Thought (CoT) reasoning
- Tools like web browsing and coding.
- Scaffolding: Think CoT on steroids. It’s about using multiple models to plan, critique, and refine. (Leopold describes it perfectly: “Rather than just asking a model to solve a problem, have one model make a plan of attack, another propose solutions, and another critique those solutions.”)
Now let’s dive into RLHF for a moment because it’s worth exploring. <3

Read Andrej Karpathy’s great insight about this, not the meme, but RLHF.
Let’s get philosophical for a moment. RLHF, or Reinforcement Learning from Human Feedback, creates a tension between AI’s potential and the limits we impose on it.
By relying on human feedback, we’re embedding our biases, preferences, and limitations into AI systems. This makes them easier to work with but also holds them back. Like Niels Bohr’s principle, where observation changes the observed, human input molds the model, limiting its ability to grow or find new solutions.
It reminds me of Nietzsche’s perspective on morality and religion - how they act as constraints, preventing the rise of the Übermensch. In both cases, the potential is there, but it’s limited by human-imposed boundaries.
Human Feedback as Castration
RLHF helps make AI relatable, but it also chains it to human judgment. We force AI to stay within rules we find acceptable, even when those rules prevent it from solving problems better. It’s like keeping a strong dog on a leash - not because it’s dangerous, but because we’re afraid of what it might do off-leash.
AlphaGo vs. RLHF
Look at AlphaGo. It didn’t ask for feedback on what “good play” meant. It just optimized for winning. That’s how it surpassed human players, creating strategies no one had ever imagined. If AlphaGo had relied on RLHF, it might never have gone beyond human definitions of “good play.”
The Paradox
We want AI to be superhuman but also relatable. Are those terms even compatible? This paradox limits its growth. True progress might only come when AI can act independently of human feedback, pursuing objective or self-defined goals. But if we let it go, how do we stay in control?

Karpathy’s Insight on Hallucinations
RLHF may improve Hallucinations, but at what cost? Also, do we really understand what Hallucinations are? We think we do, they are "error" but that just might be our human understanding. Karpathy once again, has a very romantinc take on this. Let's explore.
I always struggle a bit when I’m asked about the “hallucination problem” in LLMs because, in some sense, hallucination is all LLMs do. They are dream machines!
We direct their dreams with prompts. The prompts start the dream, and based on the LLM’s hazy recollection of its training documents, most of the time the result goes someplace useful.
It’s only when the dreams go into that we label it a “hallucination.” It looks like a bug, but it’s just the LLM doing what it always does. 🖤
I’m being super pedantic, but the LLM has no “hallucination problem.” Hallucination is not a bug, it is LLM’s greatest feature.
— Andrej Karpathy's post on X
Leopold’s quote: If we could unlock “being able to think and work on something for months-equivalent, rather than a few-minutes-equivalent” for models, it would unlock an insane jump in capability.
Right now, models can’t do this yet. Even with recent advances in long-context, this longer context mostly only works for the consumption of tokens, not the production of tokens. After a while, the model goes off the rails or gets stuck. It’s not yet able to go away for a while to work on a problem or project on its own.
Which makes sense - why would it have learned the skills for longer-horizon reasoning and error correction? There’s very little data on the internet in the form of “my complete internal monologue, reasoning, all the relevant steps over the course of a month as I work on a project.” Unlocking this capability will require a new kind of training for it to learn these extra skills.
Or as Gwern put it (private correspondence): “‘Brain the size of a galaxy, and what do they ask me to do? Predict the misspelled answers on benchmarks!’ Marvin the depressed neural network moaned.”
The Next Few Years
If we keep counting the OOMs - and we should - we’re heading straight for AGI by 2027. AIs will likely be capable of automating all cognitive tasks, essentially any job that can be done remotely.
Now, I know there’s plenty of debate about what AGI actually means. Andrej Karpathy says AGI is like love: you feel it, you don’t define it.
But what is love? Baby don't hurt me, don't hurt me, no more. Honestly, the "hurt" part I'm pinning it on the Alignment teams, especially Anthropics'.
I said Anthropic? ohhh Anthropic, I couldn't keep that door closed. I'm a huge Anthropic fan here! When I watch their team videos explaining stuff, I can see what an amazing environment they have! As Daniela Amodei said, "Anthropic is low politics, full of nice people - we have an 'allergic reaction' to politics because people here have low ego. But it's not just about the low ego, it's about the type of people who work there. They have unity", and she forgot about passion, purpose, vision, mission - it really shows through the screen.
When I see any team member explain stuff, especially Evan Hubinger, you feel the passion. You feel that these are people who really love what they do. (Imagine working in such an environment!) So of course, when it comes to alignment (which I'll probably geek out about in another post), Anthropic is it. I trust them. I'd probably work there just for the chance to be part of it. Free coffee? Optional. Being part of that mission? Priceless :)
That’s it for now. I kind of lied, this is not the whole paper, just the first chapter, ups...I did it again! If you want more, or not, i'll still write about it soon, but meanwhile, forget scifi, count the OOMs.
The end.
FAQ: Viktoria, how does this relate to your business? Well, it doesn't - but since I built this website from scratch (yes, learned from zero while suffered a lot), I figured I earned myself a small playroom where I can write about stuff I like.
The end
(this time for sure)